At Stack Exchange, we have a certain class of problems that we dub "Stack Overflow problems", which are the kind of thing that nobody ever runs into unless they're pushing systems and software as hard as we push them.
Random thought: we should do a post on various technologies that couldn’t handle the Stack Overflow load and had to be replaced.
— Nick Craver (@Nick_Craver) October 27, 2014This is one of those times - it took an interesting confluence of events to cause a problem, but other use cases might run into the same thing, so I figure it's worth doing some writing on.
A little background; when you load any page on a Stack Exchange site, you're connecting to our HAProxy load balancers, which make a backend request to the IIS servers to fetch your response. Most of our systems live behind our ASA firewalls, but half a million open connections all the time (websockets!) and ~3k HTTP requests per second is something we don't want to subject our ASAs to (and we'd need much bigger ones), so the HAProxy nodes have one of their network interfaces directly on the internet.
conntrack_must_die
..was the branch name in puppet.
HTTP servers directly on the internet, so: iptables for all the access controls! And conntrack, which can fall over under even moderate load! A lot of tuning went into problems with socket exhaustion and conntrack before my time, but a couple months back, we finally got to the point where conntrack was filling up too often, causing too many headaches on load balancer failover, and we did something about it: stopped needing it.
# in the raw table..
# most things, StackOverflow.com
-A PREROUTING -d 198.252.206.16/32 -p tcp -m tcp --dport 80 -j NOTRACK
-A OUTPUT -s 198.252.206.16/32 -p tcp -m tcp --sport 80 -j NOTRACK
-A PREROUTING -d 198.252.206.16/32 -p tcp -m tcp --dport 443 -j NOTRACK
-A OUTPUT -s 198.252.206.16/32 -p tcp -m tcp --sport 443 -j NOTRACK
# careers.stackoverflow.com
-A PREROUTING -d 198.252.206.17/32 -p tcp -m tcp --dport 80 -j NOTRACK
-A OUTPUT -s 198.252.206.17/32 -p tcp -m tcp --sport 80 -j NOTRACK
-A PREROUTING -d 198.252.206.17/32 -p tcp -m tcp --dport 443 -j NOTRACK
-A OUTPUT -s 198.252.206.17/32 -p tcp -m tcp --sport 443 -j NOTRACK
# (the astute reader might notice a bad idea here; we'll get to that)
# and in the filter table..
# most things, StackOverflow.com
-A INPUT -d 198.252.206.16/32 -p tcp -m tcp --dport 80 -j ACCEPT
-A INPUT -d 198.252.206.16/32 -p tcp -m tcp --dport 443 -j ACCEPT
# careers.stackoverflow.com
-A INPUT -d 198.252.206.17/32 -p tcp -m tcp --dport 80 -j ACCEPT
-A INPUT -d 198.252.206.17/32 -p tcp -m tcp --dport 443 -j ACCEPT
So, no more conntrack - which is great for RAM usage and great for not dropping connections when the table fills up. But instead of hitting a related/established rule at the top of the chain, all the subsequent traffic for the connection needs to traverse the chain.
Another thing that's been in iptables for forever is hard bans of particular IPs - bad crawlers, content scrapers, spammers.. suffice to say, we have to be pretty unhappy with you to give you a straight-up DROP in iptables. The commit messages tend to have profanity. Which adds another ~650 rules to traverse.
More rules to traverse without conntrack, which makes for more CPU usage from rule processing.
Oh, and we also added more rules, didn't we? That bad idea from above?
-A PREROUTING -d 198.252.206.16/32 -p tcp -m tcp --dport 80 -j NOTRACK
-A OUTPUT -s 198.252.206.16/32 -p tcp -m tcp --sport 80 -j NOTRACK
Yeah, those don't have an ACCEPT happening after them (a derp moment on my part), we're just marking the packet then continuing to evaluate the chain, for each of the listener IP/port combos. Don't do this! The PREROUTING and OUTPUT chains in the raw table both have about a hundred rules, and while the most hit rules are at the top, we're not actually dropping out of the chain after a match, just continuing to evaluate it.
All this adds up to hundreds of extra rules being checked on each input packet, and a hundred or so on each output packet. But modern CPUs are fast and checking access lists is easy work; no big deal, right? ASICs are for suckers? CPU cooked a little hotter, which we noticed but didn't worry too much about since we had expected some increase after removing conntrack.
Then this happens..
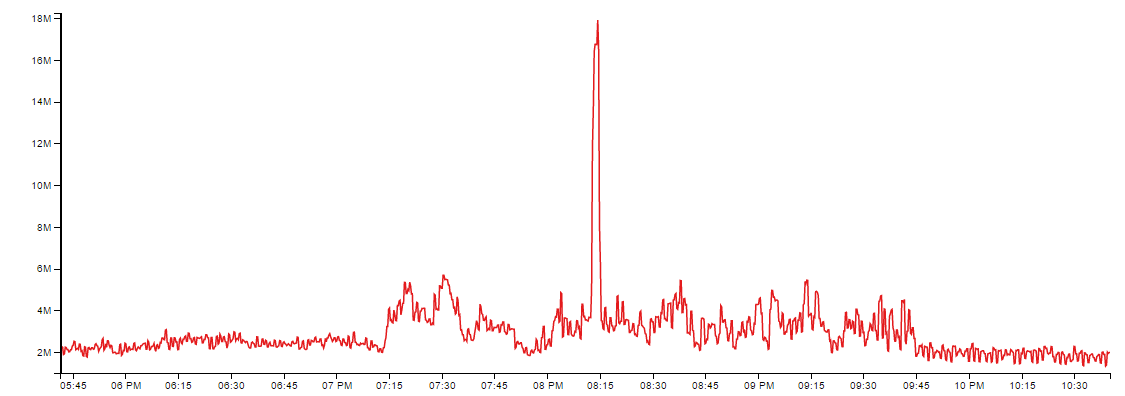
That's packets per second. People on the internet are jerks. We're pretty sure it was mostly SYN flood, but our mirror port couldn't keep up so we haven't gotten a great look at the traffic.
Processing all those packets put something over the edge in the load balancers. It triggered a fun chain reaction; VRRP between the load balancers fell apart and they started fighting over the IP addresses. At some point the NICs on the load balancers crashed, we're not quite sure what's up with that. The core switches got sick of it after a few minutes of both yelling gratuitous ARP with the same MAC and started doing unicast flooding of all those packets, which started causing havoc with other systems on that network. Cats and dogs, living together. It was a bad few minutes.
We went back and looked at what was going on with the CPU, and the cumulative effect of the increased evaluation of old rules plus the addition of new rules meant that the HAProxy process handing our most active listener addresses was pegging a CPU core even under normal load, and over half of that CPU time was due to iptables evaluation. Not so good.
Now that it has our attention...
How do we deal with this?
Well, one thing we have going for us is that the rules are all grouped nicely; a ton of the same kind of NOTRACK for listener address/port combos, a ton of blacklisted specific addresses or networks.
ipset to the rescue. It can create hashed groups of addresses or networks or address/port combinations, then a single iptables rule can evaluate against all of them at one time.
Instead of..
is it this address? no..
is it this address? no..
...(repeat 650x)...
is it this address? yes! drop that sucka.
..you get..
is it one of these addresses?
...hash lookup...
yup, ignore that jerk.
Which is potentially an enormous performance gain; iptables is only as smart as you tell it to be, and if you tell it to evaluate rules in painstaking sequence instead of "any of thems!", it'll do it.
Puppets!
So, to roll this out and make future changes easy, we put a simple little new class in our module managing the iptables rules..
class iptables::sets (
$sets
) {
package { 'ipset':
ensure => present,
}
file { '/etc/sysconfig/ipset':
content => template('iptables/ipset.erb'),
require => Package['ipset'],
notify => Service['ipset'],
}
service { 'ipset':
ensure => running,
enable => true,
before => File['iptables-file'],
}
}
And that template..
<% @sets.keys.sort.each do |setname| -%>
create <%= setname %>-replacementset <%= @sets[setname]['config'] %>
create <%= setname %> <%= @sets[setname]['config'] %>
<%- @sets[setname]['members'].keys.sort.each do |net| -%>
add <%= setname %>-replacementset <%= net %>
<%- end -%>
swap <%= setname %>-replacementset <%= setname %>
destroy <%= setname %>-replacementset
<% end -%>
(template updated 2014/11/17: a fresh set with a swap in is needed to delete members that are no longer in the hiera data)
..which gets its data from a Hiera data file like this:
"iptables::sets::sets": {
"listeners": {
"config": "hash:ip,port family inet hashsize 1024 maxelem 65536",
"members": {
"198.252.206.16,tcp:80": {"comment":"most things, StackOverflow.com - NY, HTTP"},
"198.252.206.16,tcp:443": {"comment":"most things, StackOverflow.com - NY, HTTPS"},
...
}
},
"blacklist": {
"config": "hash:net family inet hashsize 1024 maxelem 65536",
"members": {
"192.0.2.0/24": {"comment":"Insulted Nick's hair"},
...
}
}
}
All that rule work from earlier? Now the blacklist is applied with just
-A INPUT -m set --set blacklist src -j DROP
while the listener accepts are dead simple too,
# raw table
-A PREROUTING -m set --set listeners dst,dst -j NOTRACK
-A OUTPUT -m set --set listeners src,src -j NOTRACK
# filter table
-A INPUT -m set --set listeners dst,dst -j ACCEPT
Which, in total, dropped our CPU use from iptables for the hardest hit listeners from around 55% to around 2%, freeing up a ton of head room for next time we see a huge storm of packets like that.
Here's the CPU use of the processes for that specific HAProxy service, with the high one being the one handling the sockets; I bet you can tell when the change went in:
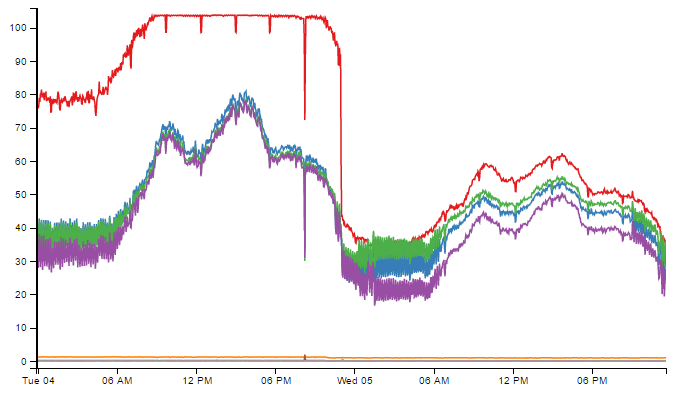
All we've really lost in the exchange is per-rule counters that we had, which were handy for determining which blacklisted addresses were still hitting us, but we can still test individual addresses by adding a rule for them, without eating a CPU alive. Pretty good deal.
Comments
comments powered by Disqus